Noni, vihdoin pääsee asentamaan Ciscon UCS:n alusta loppuun, joten tulen pistämään tänne kaikenlaista matkan varrelta ja linkkejä juttuihin, katotaan mitä tulee.
Noista itse komponenteista olikin jo aikaisemmin juttua.
Itte UCS hujahti räkkiin aika nätisti, kun mukana oli hyvät kiskot. Sähköä laitettiin tosiaan se 4kpl (n+1), C19/C20 liittimillä (
Tän näköinen liitin). Kannattaa muuten huomata, kun UCS:ää tilaa, että liittimet mitkä siinä tulee mukana on C13/C14 (
Tämmöinen). Tuossa on käsittääkseni se ongelma, että C13/C14 on 10A ja C19/C20 on sitten 16A ja jos laskee, että UCS:n yksi poweri vie 2500W, niin siitä laskettuna tulee (2500W/230V = n. 10.8), joten 10A ei riittäisi. No joku korjatkoon jos oon kauheesti väärässä :)
Kaapelointi
Alkuun pitäisi laskea vähän millaista kapasiteettia kaipaa ja minkälainen verkko on, että voi tehdä oikeanlaisen kaapeloinnin.
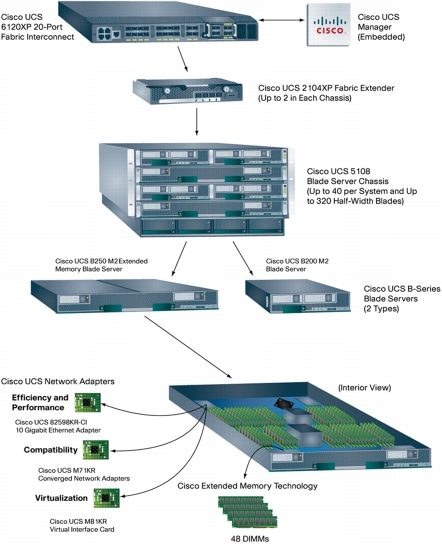
UCS FEX -> Fabric Interconnects
FEX:stä (Fiber Extension, toinen nimi IOM, eli kortti joka on UCS kehikon takana) voidaan siis vetää 1,2 tai 4 kaapelia Interconnectiin. FEX-moduuleita on 2 kpl (ok, voi olla yksi, mutta en tiedä onko se fiksua), joten kaapeleita tulee siis käytännössä 2,4 tai 8. Tämä riippuu aivan siitä miten paljon kaistaa tuohon haluaa käyttöön. Eli kun yksi kaapeli on aina sen 10Gbp/s, niin 20Gpb/s olisi ns. minimi. Ehkä kuitenkin jos ajaa levyliikenteen noista läpi myös (NFS/FCoE/iSCSI), niin melkein voisi suosia, että lähtee neljällä liikelle. Itse ajattelin näin tehdä myös tässä esimerkissä.
Mutta tietysti jokainen asennus on erilainen ja näiden FEX:stä lähtevien kaapeleiden määrä vaikuttaa suoraan siihen, miten monta UCS-kehikkoa yhteen clusteriin voi laittaa.
Blogi-kirjoitus UCS:n skaalautuvuudesta, jossa myös taukukko noista kaapeli / palvelin määristä:
http://rodos.haywood.org/2009/06/scaling-cisco-unified-computing-system.html
Kuvana se näyttää tältä:
Vasemmanpuoleinen on FEX A ja oikea sitten FEX B. On tärkeää huomata, että FEX A:sta kaapelit menevät vain toiseen fabriciin, eikä koskaan sekoiteta niitä keskenään. Eli FEX A:sta kaapelit vain yhteen 6120XP (tai 6140) -kytkimeen.
Kaapeleista vielä sen verran, että jos käytössä on 1 kaapeli, niin kaikkien palvelimien liikenne kulkee sitä kautta (doh). Kahdella kaapelilla liikenne muuttuu niin, että parilliset serverit menevät porttia 1 pitkin ja parittomat porttia 2 pitkin. Neljällä sitten taas niin, että palvelimet 1,5 -> port1, 2,6 -> port2, 3,7 -> port3, 4,8 -> port4. UCS tekee tämän itsestään, eikä siihen voi vaikuttaa, mutta ihan kurisioteettina.
Fabric interconnect (6120/6140XP)
Itse kytkimet, missä oikeastaan kaikki älykin on, näyttääpi tältä:
(Ärsyttävää oli muuten, että noi powerit on etupuolella..)
Kaavakuvana:
Ihan vasemmalla on L1/L2 portit, jotka vedetään toisen kytkimen vastaaviin portteihin. Tän kautta kytkimet vaihtavat tiedot ja pitävät itsensä keskenään synkassa. Portit ovat 1G eth-portteja, joten tavallinen CAT5 tms kaapeli kelpaa. L1/L2:n vieressä on 2 kpl Management portteja, joten niihin sitten hallinta yhteys. Hallinta tarvitsee (jos tekee clusterin) 3 IP-osoitetta. Muuten IP-osoitteita ei sen enempää tässä vaiheessa menekään (jotta palvelimen hallinta (KVM yms) toimii, niin se muistaakseni vaatii sitten erikseen IP-osoitteet, mutta niistä myöhemmin).
Kytkimet sitten arpovat keskenään kummasta tulee primary ja kummasta subordinary.
Tässä on hyvä kirjoitus, miten UCS toimii, jos kytkimet menettävät yhteyden toisiinsa.
http://blog.aarondelp.com/2010/02/how-cisco-ucs-deals-with-split-brains.html
Porteista vielä, että 8 ensimmäiseen porttiin voi myös laittaa 1G SFP+ -optiikan. Muuten kaikki portit ovat 10G SFP+. Joten ei pitäisi olla merkitystä minkä kaapelin kytkee mihinkin..
Kuvan slot2, eli expansion slottiin sai kiinni joko lisää ETH-portteja tai sitten fiber channellin. FC:ssä kaapelit vedetään siitä FC-kytkimiin, mutta tästä lisää myöhemmin.
Itse UCS:n verkottamisesta, niin peruslähtökohta on suunnilleen tämmöinen (Ciscon sivuilta):
Tähän rakennetaan muuten aika identtinen setuppi, paitsi uplinkkejä tulee olemaan vain yksi per Interconnect (siis yksi kaapeli per interconnect -> kytkin, eli 2 kpl per interconnect, kun kytkimiä on kaksi vikasietoisuuden kannalta.. no kuten kuvassakin on:)).
Tämä nyt lähinnä siksi, että 10G riittää hyvin, homma pysyy yksinkertaisena, port-channelin kanssa on ollut ihmisvirheitä ennenkin, joten sillä mennään. Meillä ei ole nexuksia, joten vPC:tä ei voi käyttää.
Näiden konffaamisesta sitten joskus juttua, kun pääsen itsekin hommassa eteenpäin.
Sillä välin tää on ihan loistava pätkä, missä on hyvin selitetty kaikki tuon verkoista:
http://bradhedlund.com/2010/06/22/cisco-ucs-networking-best-practices/
Ens kerralla UCSM:n initial configuraatio jne tulossa.








{kind=link}