Cisco toi UCS:n (aka. Project California) vähän aikaa sitten markkinoille. Sen tarkoitus olisi Ciscon sanoin yhdistää niin verkko, levy (storage), palvelin virtualisointi yhdeksi kokonaisuudeksi.
Ciscon ajattelutapa eroaa aika paljon siinä, että kehikon "aivot" tuodaan kytkimeen sensijaan, että jokaisessa kehikossa olisi omat "aivot", kuten mm. HP ja Dell tekee. Tämä tietysti auttaa siinä, että kehikko itsessään on vain rautaa ja hintaa saadaan siinä alaspäin, joskin kytkimet tietysti maksavat enemmän. Samoin Ciscon PALO-kortti (M81KR) on erittäin mielenkiintoinen ja tarjoaa varmasti jännittäviä konffaushetkiä ja vähän muuttaa tapoja tehdä asioita.
Hommahan koostuu alla olevan kuvaisesti seuraavista komponenteista (Ciscon sivuilta poimittu kuva)
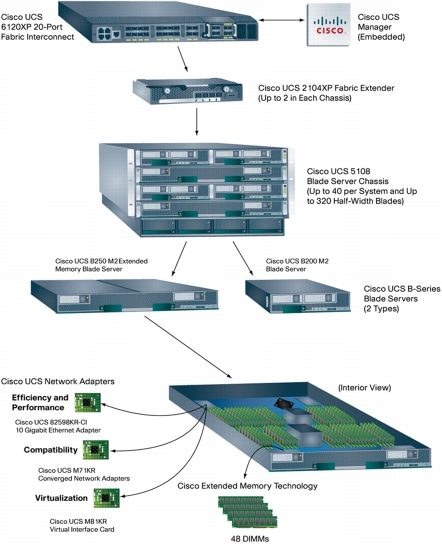
Alhaalta ylöspäin. Taino, keskeltä alas ja sitten ylös.
Keskellä on kehikko (5100 malli), johon saa 8 puolileveää tai 4 täysleveää palveinta kiinni.
Taakse laitetaan 2 kpl Fabric Extenderit (UCS 2104XP), joista yhdestä FEX:istä saa 4 kpl 10G yhteyttä kiinni UCS-kytkimiin. Kehikossa on 8 tuuletinta. Sähköä se muistaakseni söi 4 x 2500W powereita, jotka pystyivät olemaan muutamalla eritavalla kytkettyinä. Itse suosisin n+1 mallia. Korkeus on 6RU.
Kehikossa itsessään ei ole mitään älyä, joten siitä ei ole kauheasti mitään sen ihmeellisempää kerrottavaa.
Bladeja taitaa tällä hetkellä olla saatavilla B200 (puolileveä) ja B250 (täysleveä).
B2x0 -sarjalaiset tukevat Intelin 55xx prosessoreja. Ilmeisesti on tullut myös B4xx sarjalaisia, joissa on sitten Intelin 56xx ja 75xx malleja, mutta niistä en tiedä sen tarkemmin.
B200:een saa maksimissaan 96GB muistia (12DIMM) ja B250 tukee 384GB (48DIMM).
B200 saa yhden mezzanine kortin ja B250:een 2. Näinollen B200 thruput on 20Gbps max ja B250 40Gbps.
Mezzanine kortteja on seuraavanlaisia:
• Cisco UCS 82598KR-10 Gigabit Ethernet Network Adapter
• Cisco UCS M71KR-Q QLogic Converged Network Adapter
• Cisco UCS M71KR-E Emulex Converged Network Adapter
• Cisco UCS M81KR Virtual Interface Card
Tulen käymään läpi tuota M81KR korttia enemmän jatkossa, koska tuo on yksi syy, miksi Ciscon UCS on kiinnostava.
Kehikosta mennään FEX:in kautta UCS kytkimiin (6120/6140 mallit). FEX:stä kytkimiin laitetaan kaapeleita tarpeen mukaan. Muistaakseni joko 1,2 tai 4 10G yhteyttä (per FEX). Maksimi thruput on silloin 80Gpbs per kehikko.
UCS kytkimistä (Fabric Interconnect) sitten tulee ihan omia juttuja. Kytkimissä on oikeastaan kaikki mitä UCS itsessään on. Yhteen UCS järjestelmään voi kytkeä 40 UCS kehikkoa (max 320 puolileveää palvelinta). Jokatapauksessa kytkimessä on 20 tai 40 10Gpbs porttia (SFP+) ja lisämahdollisuutena voi siihen laittaa 8 porttisen 1/2/4Gbps FC (Fiber Channel) kortin, 6 porttisen 1/2/4/8Gbps FC-kortin, 6 porttinen 10Gbps eth-kortti tai 4 FC + 4 eth 10Gbps kortin.
Hyvä, sekava kirjoitus.. kyl tää tästä :)



